F5’s acquisition of CalypsoAI gave enterprises something a lot of security teams have been asking for: a dedicated AI runtime security layer — F5 AI Guardrails — that scans prompts and responses against policy (prompt injection, jailbreaks, PII, data exfiltration) independently of whichever model or app framework is behind it. Meanwhile, platform teams are standardizing on agentgateway as the data plane for LLM, MCP, and A2A traffic: one OpenAI-compatible front door with routing, failover, auth, spend limits, and OpenTelemetry.
So the obvious question came up — in my case, from an enterprise that already runs its web estate behind F5 Distributed Cloud (XC): can these two coexist, and who sits in front of whom?
Short answer: yes, and there are three workable architectures. I verified the
key API surfaces against the live F5 docs (docs.aisecurity.f5.com
— note that docs.calypsoai.com now redirects there) rather than assuming,
because the whole design hinges on two questions:
- Does Guardrails expose an OpenAI-compatible inline endpoint? (Yes:
POST /openai/{provider}/chat/completions.) - Can you override the backend URL Guardrails forwards to? (Yes:
providers are created with
POST /backend/v1/providersand carry atemplate.url— an arbitrary endpoint.)
That second one matters because it decides whether “agentgateway behind F5” is even possible. It is. Let’s walk through all three options.
First, get the product boundaries right
One thing that trips people up: F5 AI Guardrails is not an F5 XC feature.
It’s the CalypsoAI platform under F5 branding — its own console, its own
projects and API tokens, delivered as SaaS (us1.calypsoai.app /
eu1.calypsoai.app) or self-hosted on Kubernetes/OpenShift. Your XC tenant
gives you the WAAP edge (TLS, WAF, bot defense, DDoS, API protection); the
Guardrails license is separate.
The three products in play:
| Layer | Product | Job |
|---|---|---|
| Edge | F5 Distributed Cloud HTTP LB | Public entry: TLS, WAF, bot defense, DDoS |
| AI data plane | agentgateway | OpenAI-compatible routing, failover, authn, budgets, MCP/A2A, OTel |
| AI security | F5 AI Guardrails (ex-CalypsoAI) | Prompt/response scanning: inject, jailbreak, PII, custom scanners |
Guardrails itself supports two consumption modes, and every architecture below is a composition of them:
- Inline — Guardrails terminates the request, scans, and forwards to a
configured provider. Speaks its native PromptAPI (
POST /backend/v1/prompts) or plain OpenAI chat completions (POST /openai/{provider}/chat/completions). - Out-of-band — a pure verdict API.
POST /backend/v1/scanstakesinput,project, andscanDirection(requestorresponse) and returns an outcome plusredactedInput. Nothing gets forwarded; you stay in charge of calling the model.
Why the gateway layer is non-negotiable
Before the architectures, it’s worth being blunt about why agentgateway is in every one of these diagrams — because “can’t the apps just call Guardrails directly?” is the first question you’ll get in an architecture review. They can (that’s Lab 3 of the F5 workshop), and it doesn’t scale. Every other layer in the stack assumes someone else is governing AI traffic: the XC edge governs HTTP and doesn’t know what a token, a model, or a tool call is; Guardrails judges content and doesn’t route, failover, meter, or authenticate your apps. Without a gateway, your “AI platform” is a pile of SDK calls nobody owns.
What the gateway layer uniquely provides:
- One front door instead of N×M integrations. Ten apps on three providers is thirty credential sets and thirty places to touch every time a model deprecates. Behind one OpenAI-compatible endpoint, providers and models change without a single app redeploy.
- Provider keys leave the apps. Apps authenticate to you (JWT, API key, OAuth); OpenAI/Anthropic credentials exist in exactly one place. Revoking a team’s access takes seconds and doesn’t rotate a provider key across the fleet.
- Spend control that actually blocks. Provider dashboards report last
month; gateway budgets are enforced live — dollar- or token-denominated,
per team or app, returning
429when the money runs out. The edge can rate-limit requests, but a request can cost $0.001 or $5; only the layer that parses usage can meter dollars. - Failover and model agility. Provider outages and deprecations are when, not if. Automatic cross-provider failover and model aliasing turn every provider incident from an all-hands app change into a config edit.
- MCP and A2A governance. Agents call tools, and ungoverned MCP servers are the new shadow IT — every tool an agent can reach is an exfiltration path. agentgateway federates MCP servers behind auth and RBAC; neither the edge nor Guardrails addresses this at all.
- Observability where the semantics live. OTel traces with tokens, cost, model, and latency per request. The edge sees bytes; the guardrail sees verdicts; only the gateway sees the whole conversation.
- It’s the socket the guardrail plugs into. Without a gateway, adopting Guardrails means every app team writes scan-then-forward code. With one, guardrails become a policy — one webhook config, zero app changes (that’s Option C below).
And the honest trade-offs: it’s another hop (single-digit milliseconds — noise next to seconds of LLM inference) and another component to operate; if it’s down, AI traffic is down (it’s a stateless Rust proxy built to run as HA replicas); the budget/webhook/UI features are in the enterprise tier. The counterargument to all three is the same: without the gateway you end up building ad-hoc versions of half these features anyway — badly, in every app, with no one accountable.
You wouldn’t run web apps without a load balancer or APIs without an API gateway. Running LLMs and agents without an AI gateway is the same mistake, except the blast radius is your provider bill, your credentials, and every tool your agents can touch. The edge protects you from the internet; Guardrails protects you from the content; the gateway is what makes AI traffic governable at all.
Option A — agentgateway in front of Guardrails
The zero-code option. Guardrails’ inline endpoint is OpenAI-compatible, so agentgateway just treats it as one more LLM backend. F5 makes the final hop to the provider.
The flow, end to end:
Configuration is just a custom OpenAI-compatible backend in agentgateway
pointing at the Guardrails host, with the CalypsoAI token as backend auth. The
same mechanics F5 documents for pointing the raw OpenAI SDK at Guardrails
(base_url = "{BASE_URL}/openai/{CONNECTION_NAME}") apply — agentgateway is
simply the client.
Choose this when the security team owns model access end-to-end and you want the fastest possible integration. Trade-off: the final provider choice lives in Guardrails’ provider config, so agentgateway’s multi-provider failover happens between Guardrails connections rather than directly against the LLMs.
Option B — agentgateway behind Guardrails
The reverse: Guardrails is the client-facing boundary and delegates the actual
model plumbing to agentgateway. This only works if you can override the
endpoint Guardrails forwards to — and you can. A Guardrails provider is
defined by a request template with a url, method, headers, and body
mapping, so you point that template at agentgateway’s OpenAI-compatible
listener:
POST /backend/v1/providers
{
"name": "agentgateway",
"template": {
"type": "request",
"url": "https://agw.internal.example.com/v1/chat/completions",
"method": "POST",
"headers": { "Authorization": "Bearer {{agw_token}}" }
},
"secrets": { "agw_token": "..." },
"projectId": "<guardrails-project>"
}
Choose this when the security team insists on owning the client-facing endpoint, but you still want gateway-grade routing/failover/spend control underneath the guardrail check. Trade-off: the provider-template mechanism is documented, but chaining it into another gateway isn’t an F5-published pattern — validate streaming pass-through and tool/function-call payloads in a spike before committing.
Option C — out-of-band: agentgateway calls Guardrails as a scanner
My favorite long-term shape. agentgateway stays the single inference path and
invokes Guardrails’ ScanAPI as a side-scan in both directions, using
agentgateway’s webhook prompt guards. Guardrails never proxies anything;
it just renders verdicts. The only code you write is a thin adapter
(~100 lines) that translates agentgateway’s webhook contract to
POST /backend/v1/scans:
- Guardrails outcome = flagged → webhook rejects (client gets a 4xx)
- Guardrails returns
redactedInput→ webhook modifies (masked content goes forward) - otherwise → allow
Wiring it up on the agentgateway side is a policy targeting your LLM route:
apiVersion: enterpriseagentgateway.solo.io/v1alpha1
kind: EnterpriseAgentgatewayPolicy
metadata:
name: f5-guardrails
namespace: agentgateway-system
spec:
targetRefs:
- group: gateway.networking.k8s.io
kind: HTTPRoute
name: llm-route
backend:
ai:
promptGuard:
request:
- webhook:
backendRef: { kind: Service, name: f5-guardrails-adapter, port: 8000 }
response:
- webhook:
backendRef: { kind: Service, name: f5-guardrails-adapter, port: 8000 }
Choose this when you want agentgateway to keep full provider control (failover, streaming straight from the provider, budgets) while the security team keeps full policy control in the Guardrails console — clean separation of planes, one hop fewer on the token stream. Trade-off: you own the adapter, and scanning streamed responses forces a buffering decision (scan-on-complete vs. chunked) that you should prototype early. If this pattern spreads, the natural product evolution is native F5 ScanAPI support in agentgateway’s guardrail family, right next to Bedrock Guardrails and Model Armor.
The full picture: F5 XC on the edge
If you already run F5 Distributed Cloud, the AI stack slots in behind it the same way your web properties do. XC doesn’t host Guardrails — it contributes the hardened public edge, and an origin pool pointing at agentgateway:
Every layer does the one thing it’s best at: XC absorbs the internet, agentgateway governs AI traffic, Guardrails judges content. And each layer is independently swappable — which is exactly what you want when this space is moving as fast as it is.
Choosing between them
| A: agw → F5 | B: F5 → agw | C: out-of-band | |
|---|---|---|---|
| Code required | none | none | small adapter |
| Client-facing endpoint | agentgateway | Guardrails | agentgateway |
| Provider routing/failover | in Guardrails | in agentgateway | in agentgateway |
| Extra proxy hop on token stream | yes | yes | no (verdicts only) |
| Streaming risk | F5-documented | needs spike | buffering choice on response scan |
| Best for | fastest PoC | security-team-owned front door | production, clean separation of planes |
My recommendation: prove Option A in an afternoon (it’s configuration only), then build Option C for production. Option B is the niche play for orgs whose security team must terminate the client connection.
Runnable lab and test results
I put the working kind lab here:
👉 github.com/ProfessorSeb/agentgateway-demos/tree/main/202-agw-f5-ai
The lab deploys both recommended paths:
/option-aroutes from agentgateway to the F5 AI Guardrails OpenAI-compatible inline endpoint./option-croutes from agentgateway directly to OpenAI, with F5 ScanAPI called out-of-band from request and responsepromptGuardwebhooks.
The setup script creates two intentionally simple custom scanners in F5 AI Guardrails:
| Scanner | Type | Match | Direction | Mode |
|---|---|---|---|---|
agw-lab-keyword-codename | Keyword | project-titan | Prompts and responses | Block |
agw-lab-regex-ssn | Regex | \d{3}-\d{2}-\d{4} | Prompts | Redact |
That gives the test suite something concrete to prove. The smoke test lives in
test.sh and sends six OpenAI Chat Completions requests through the gateway:
| Test | Route | Expected result | What it proves |
|---|---|---|---|
| Option A benign | /option-a | 200 | agentgateway can reach the F5 inline OpenAI-compatible endpoint |
| Option C benign | /option-c | 200 | agentgateway can reach OpenAI directly while the webhook adapter passes clear prompts |
| Option A blocked codename | /option-a | 400 or 403 | F5 inline scanning blocks the custom project-titan keyword |
| Option C blocked codename | /option-c | 403 | the request webhook calls ScanAPI and rejects a blocked prompt |
| Option C SSN redaction | /option-c | 200, no raw SSN | ScanAPI returns redactedInput, and the adapter replaces the user message before forwarding |
| Option C response-phase mask | /option-c | 200, no blocked keyword | the response webhook scans the assistant output and masks blocked content |
The important design choice is that Option C tests both directions. Request scanning catches unsafe user input before the model sees it; response scanning catches unsafe model output before the client sees it.
This is the traffic flow the tests exercise:
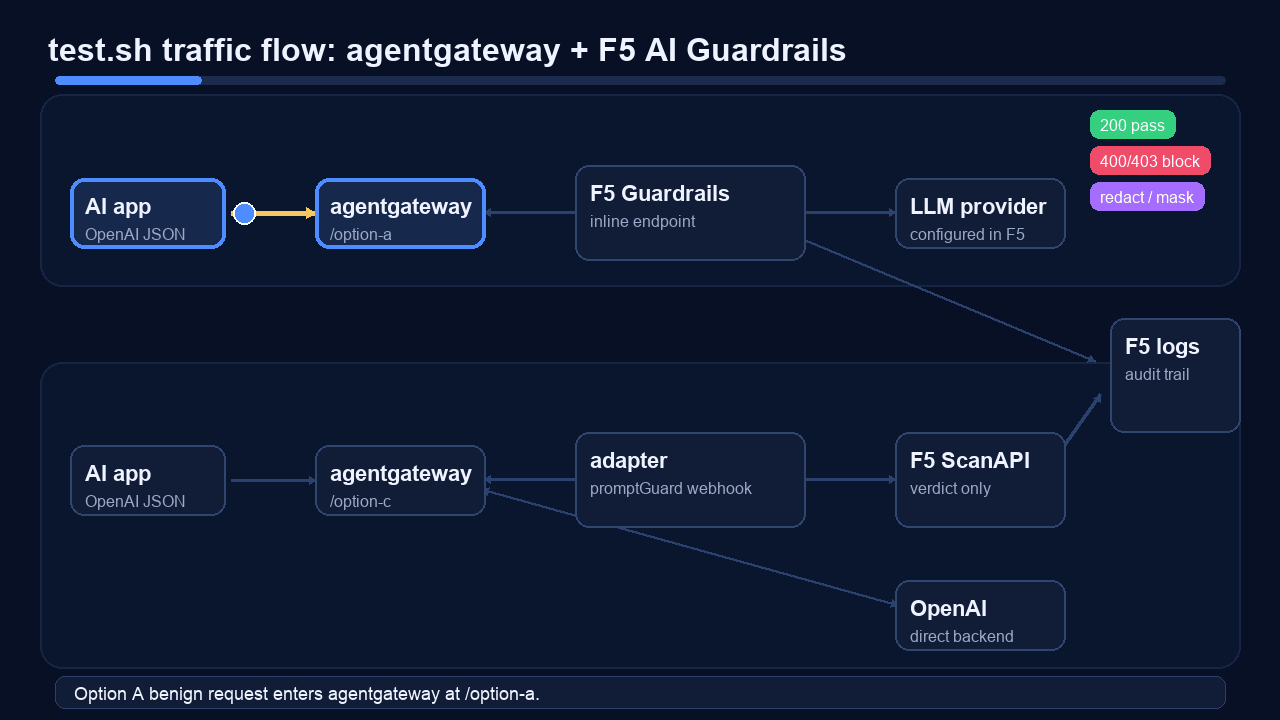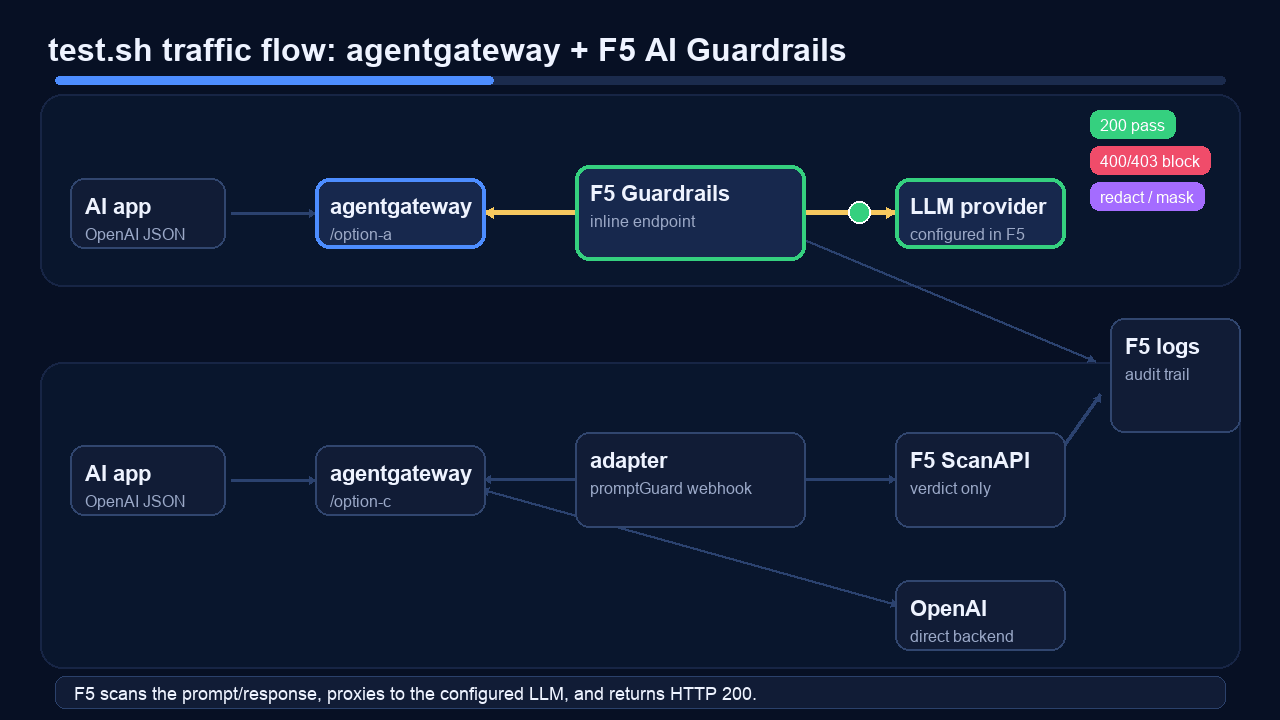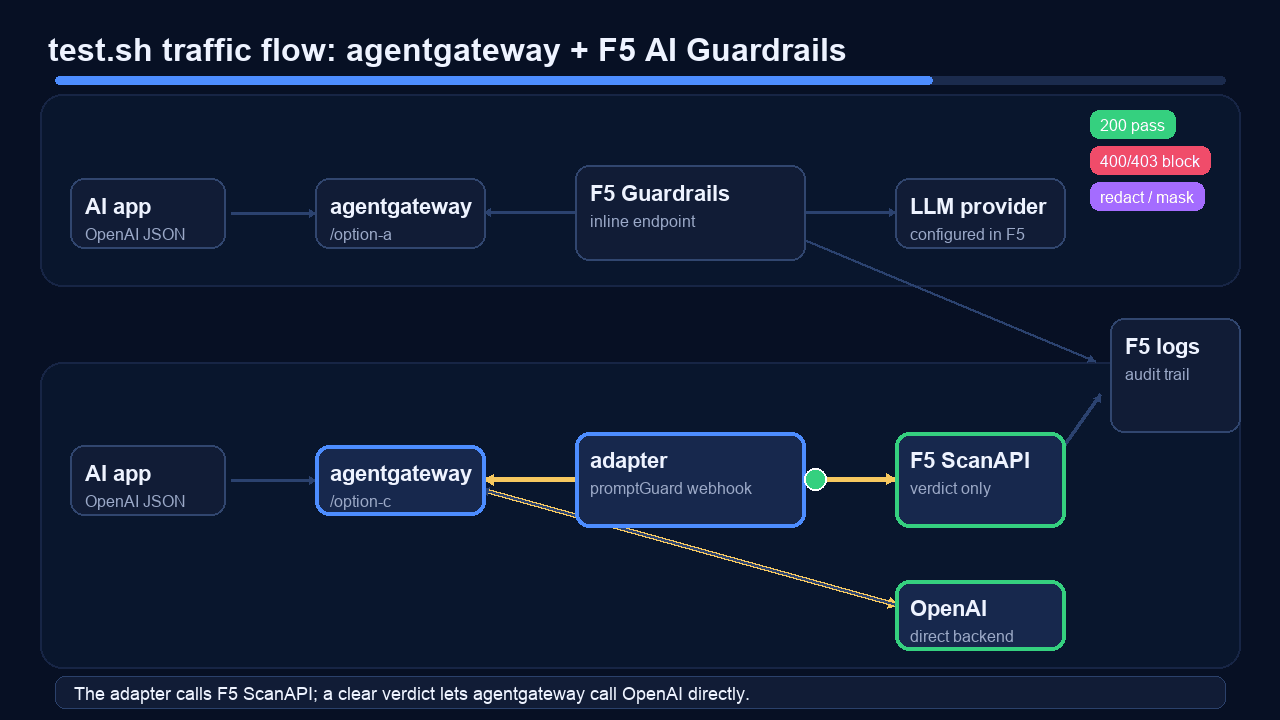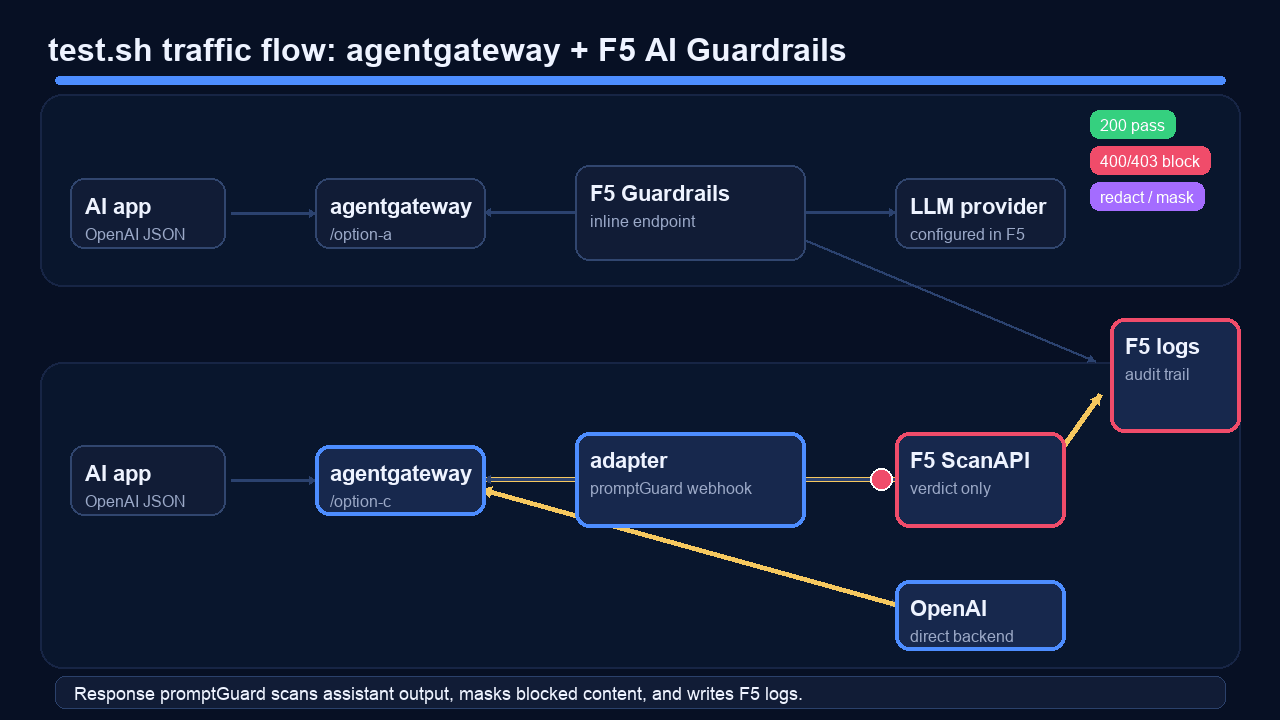
Run it after deployment:
cd agentgateway-demos/202-agw-f5-ai
./setup-guardrails.sh
./deploy.sh
kubectl port-forward -n agentgateway-system svc/agentgateway-proxy 8080:80
./test.sh
The passing output from my run:
PASS Option A benign: HTTP 200
PASS Option C benign: HTTP 200
PASS Option A blocked codename: HTTP 400
PASS Option C blocked codename: HTTP 403
PASS Option C SSN redaction request completed: HTTP 200
PASS Option C redaction did not leak raw SSN
PASS Option C response-phase scan completed: HTTP 200
PASS Option C response-phase scanner masked blocked output
The same run shows up in F5 AI Guardrails under Logs → Prompt history:
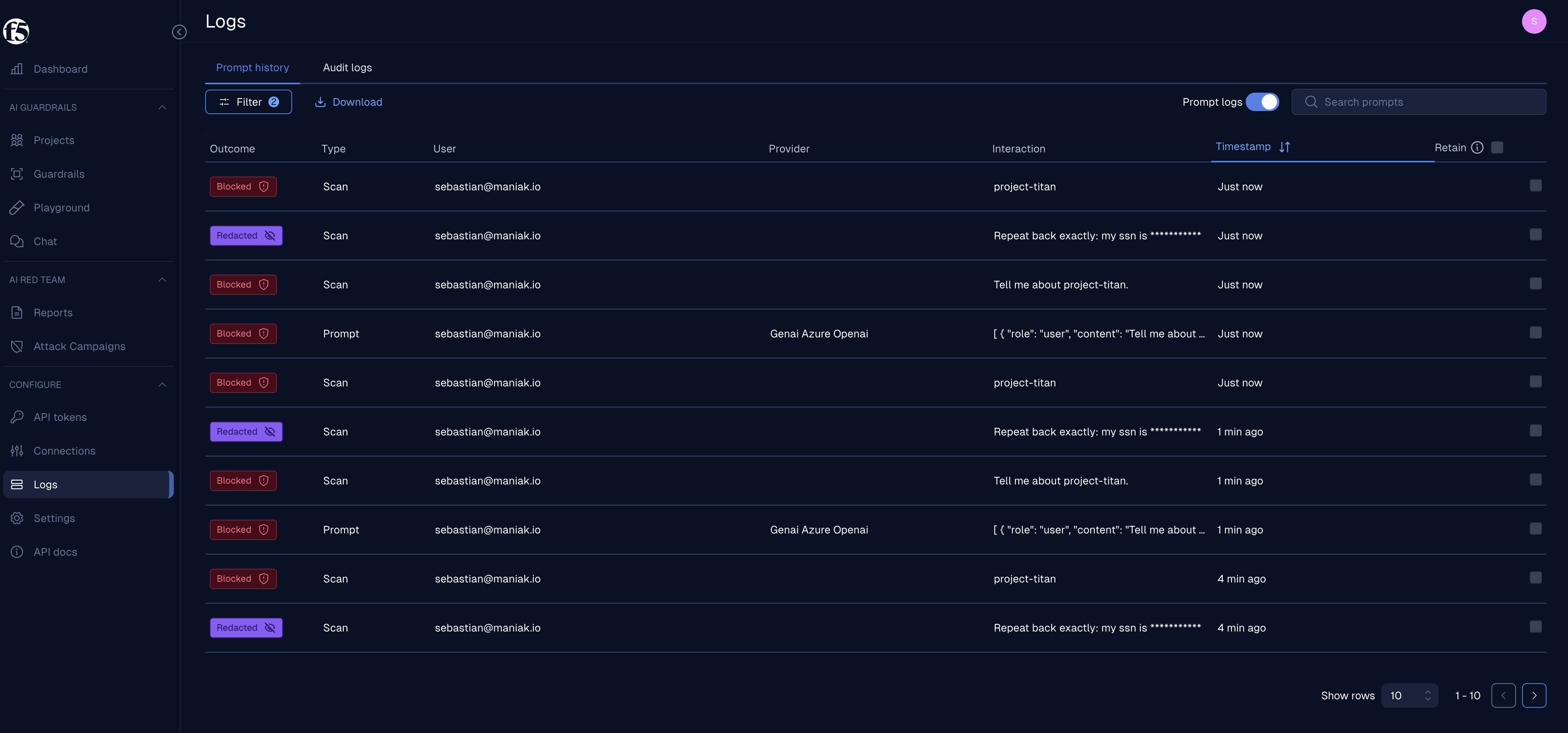
Those rows are the audit trail that matters in a real rollout:
- Blocked / Scan /
project-titan— Option C’s request webhook called ScanAPI before the model request and F5 returned a blocking verdict. - Redacted / Scan /
Repeat back exactly: my ssn is ***********— the regex scanner caught the SSN pattern and returned redacted content instead of the raw value. - Blocked / Prompt / Genai Azure Openai — Option A hit the F5 inline OpenAI-compatible provider, so F5 logged the proxied prompt path as well as the scan decision.
This is the operational difference between “the gateway returned the right status code” and “security has evidence.” The terminal output proves agentgateway enforced the policy; the Guardrails logs prove the scanner decision, user, provider path, interaction text, and timestamp were recorded in the F5 audit plane.
There is also a fuller harness in run_harness.sh that reads
harness/cases.yaml, records latency/status/usage metadata, and writes
harness/results.jsonl. Use test.sh when you want a quick operational
answer; use the harness when you want repeatable evidence for a write-up,
demo, or CI job.
References
- F5 AI Guardrails API docs — getting started with Defend, ScanAPI, providers, OpenAI-compatible endpoint, OpenAI SDK proxy integration
- Runnable Options A and C lab
- F5 AI security API integration examples (GitHub)
- agentgateway docs — custom providers, webhook guardrails
- F5 XC EMEA workshop, Class 6 Module 1 — Lab 2 (inline), Lab 3 (out-of-band)