In a previous post I showed that Enterprise agentgateway can cut your LLM bill by changing how GitHub’s MCP tools are presented to the model — its toolMode (Standard / Search / Code) shrinks the tool-catalog tax, the 4,781 tokens of tool schema re-injected on every turn.
But that’s only one line item on the bill. Headroom attacks a different one: it’s a compression proxy that shrinks the content payload — the verbose GitHub JSON results, file contents, and conversation history — before they ever reach the model. It claims 60–95% token savings, including “GitHub issue triage 73%.”
So the obvious question: they touch different layers, so do the savings stack? If AgentGateway removes the catalog tax and Headroom removes the payload tax, do you get both by running them together — or does one make the other redundant?
I measured it. All the code, manifests, harness, judge, dashboard, and raw results are in the demo repo:
👉 sebbycorp/agentgateway-demos / 105-ent-headroom-comp-tokenomics
TL;DR: Yes — but only when there’s real payload to compress, and not for free. On a large repo, Headroom stacks on top of every AGW mode (Code −63%, Search −36%). On a small, catalog-dominated repo it barely helps and actually makes Standard mode 49% more expensive by busting the provider’s prompt cache. And it trades a little accuracy on exact-identifier tasks.
Two knobs, two layers
This is the whole mental model, so it’s worth being precise:
| What it reduces | How | |
|---|---|---|
| AGW tool modes | the tool-catalog tax + orchestration round-trips | Search: 28 tools → 2 meta-tools (−91% catalog). Code: N calls → 1 round-trip, summary-only result |
| Headroom | the content payload + history | ML/AST/JSON compressors (SmartCrusher, CodeCompressor, the Kompress model), reversibly |
AGW shrinks the schemas and round-trips. Headroom shrinks the result data and history. Because they act on different parts of the request, they can — in principle — compound. The experiment is whether they actually do.
The setup at a glance
| Component | Value |
|---|---|
| Backend | GitHub’s external remote MCP server — api.githubcopilot.com/mcp/readonly (28 read-only tools) |
| Front door | Enterprise agentgateway (toolMode Standard/Search/Code; injects the GitHub PAT as a Bearer token) |
| Compression layer | Headroom proxy (headroom proxy, OpenAI-compatible), upstream pointed at the AGW /openai route |
| Model | gpt-5.5 via the agentgateway /openai route |
| Scope | A small repo (sebbycorp/agw-tokenomics-sandbox) and a larger one (sebbycorp/k8s-iceman), both read-only-pinned |
| Matrix | 3 tool modes × Headroom OFF/ON × 2 repos = 12 cells, 5 questions each + an LLM-judge quality score |
Architecture — two independent switches in one pipeline
The key insight that makes the test clean: the two knobs sit on different arrows.
┌─ Headroom OFF ─► AGW /openai ──► OpenAI gpt-5.5
harness ──build request──>┤
(catalog baked in └─ Headroom ON ──► Headroom proxy ─► AGW /openai ─► OpenAI
per AGW tool mode) (compresses payload + history)
│
└──/mcp/gh-{std,search,code}── AGW (toolMode) ──TLS+PAT──► GitHub remote MCP
- Knob 1 — AGW
toolModeacts on the MCP catalog (the/mcp/gh-*arrow). - Knob 2 — Headroom acts on the LLM request body (the
/openaiarrow). OFF = harness posts straight to AGW; ON = it posts to the Headroom proxy, which compresses and forwards to AGW.
Crucially, the AGW catalog effect is independent of which LLM URL is used: the harness bakes the tool catalog into the request from the MCP tools/list response, so the two knobs stay orthogonal. Headroom forwards to AGW (not OpenAI directly) so AGW still supplies the model + key and traces every call.
A gotcha worth flagging. Headroom is OpenAI-compatible at
/v1/chat/completions, and you point its upstream at AGW withOPENAI_TARGET_API_URL. But out of the box, its semantic cache and CCR tool-injection broke the Search/Code tool-orchestration flow — every Search/Code request through Headroom failed with an MCPTaskGrouperror until I launched it with--no-cache --no-ccr-inject-tool --no-ccr-marker. In front of an MCP tool-calling agent, those flags are mandatory. (A quick sanity check that compression is actually happening: the same 29 KB tool-result blob went 10,859 → 9,772 prompt tokens through the proxy.)
The numbers
Single run, gpt-5.5 list-price, cache-aware. Δ = the Headroom saving (ON vs OFF): positive means ON is cheaper, negative means ON is more expensive.
Small repo — agw-tokenomics-sandbox
| AGW mode | OFF cost | ON cost | Headroom Δ | OFF quality | ON quality |
|---|---|---|---|---|---|
| Standard | $0.0289 | $0.0432 | −49% (worse) | 5.0 | 5.0 |
| Search | $0.0149 | $0.0138 | +7% | 5.0 | 4.2 |
| Code | $0.0315 | $0.0204 | +35% | 5.0 | 4.8 |
Large repo — k8s-iceman
| AGW mode | OFF cost | ON cost | Headroom Δ | OFF quality | ON quality |
|---|---|---|---|---|---|
| Standard | $0.0424 | $0.0391 | +8% | 5.0 | 4.2 |
| Search | $0.0269 | $0.0173 | +36% | 4.8 | 4.4 |
| Code | $0.0623 | $0.0233 | +63% | 3.4 | 4.6 |
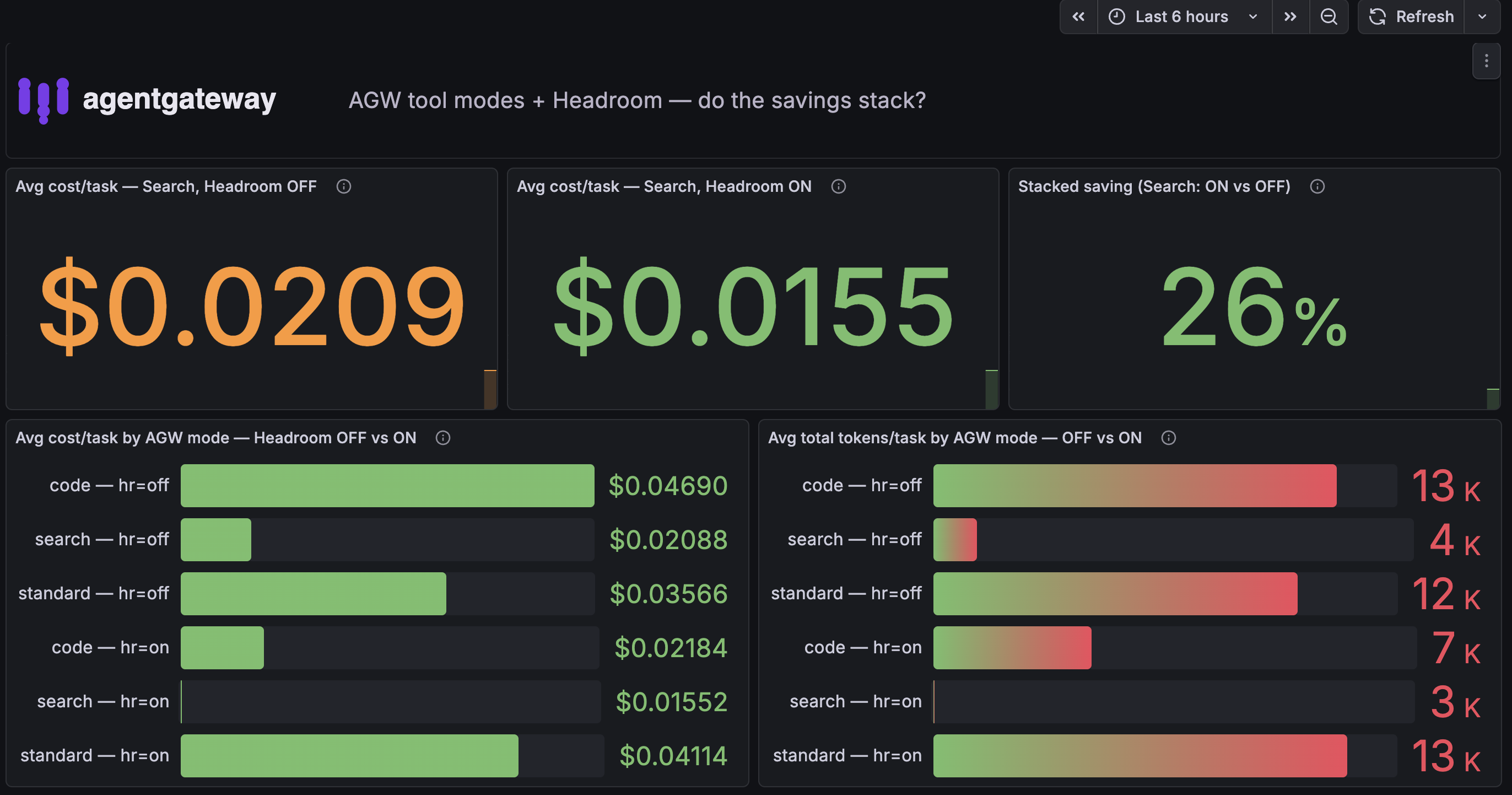
The live Grafana dashboard (metrics pushed via Prometheus pushgateway) shows the blended cross-repo picture — Search drops from $0.0209 → $0.0155, a 26% stacked saving:
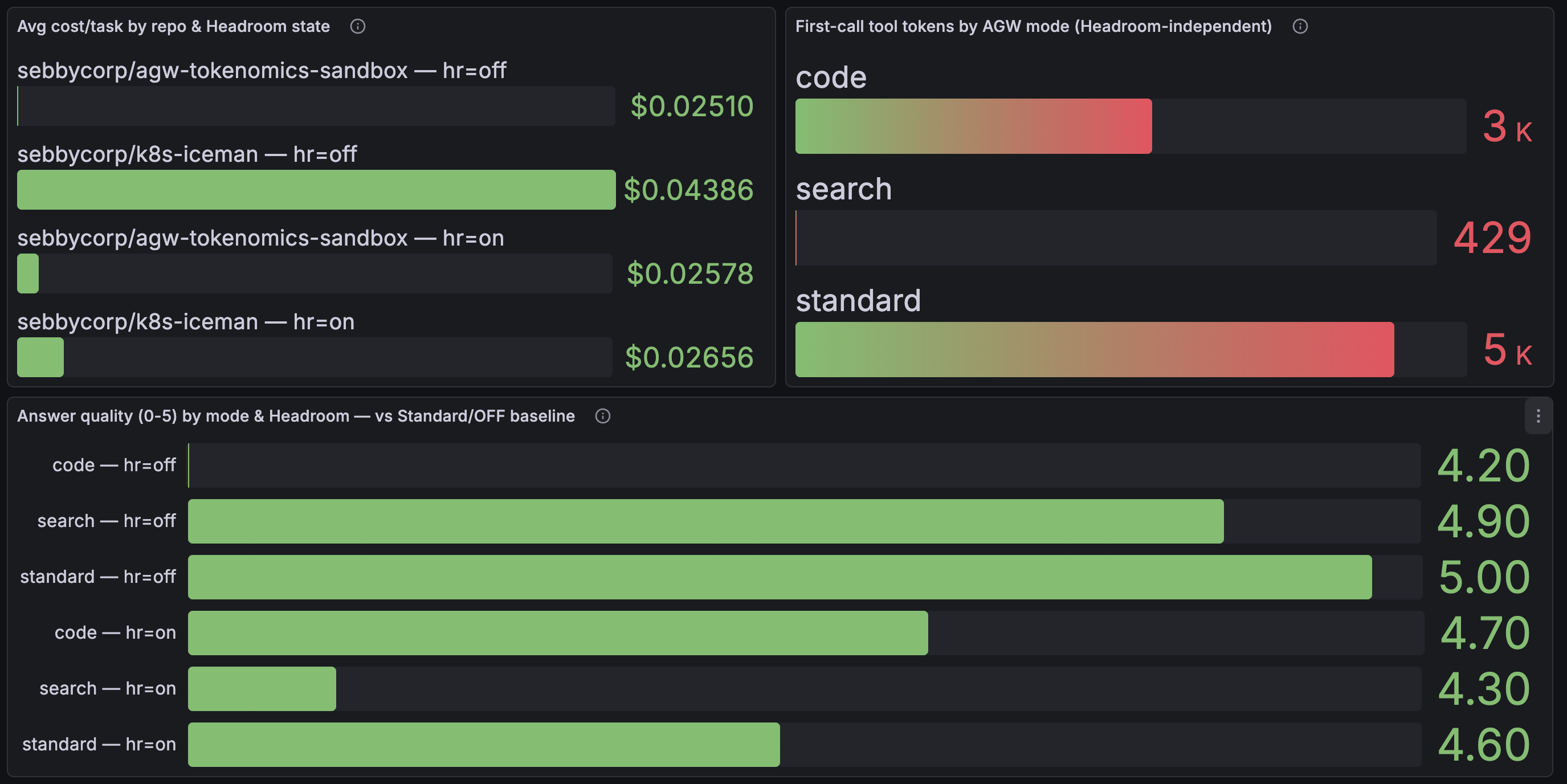
And the per-repo + quality detail — note Search’s first-call tool context is just 429 tokens (the AGW catalog win, independent of Headroom), and the answer-quality panel that keeps the comparison honest:
Why it comes out this way
1. On a large repo, the layers stack. Big result payloads give Headroom something to compress, and AGW has already collapsed the catalog. The biggest stack is Code + Headroom (−63%) — Code returns summaries only, and Headroom squeezes those further. The cheapest reliable cell overall is Search + Headroom ($0.0173): AGW removes the −91% catalog tax, Headroom removes the result-JSON tax.
2. On a small repo, Headroom can backfire. With little result data to compress, its upside is small — and on Standard mode it loses 49%. The reason is subtle but important: Headroom rewrites the prompt on every turn, which busts gpt-5.5’s prefix cache. On a small workload the big, stable 28-tool catalog is exactly what caches well, so the cache you destroy is worth more than the payload you compress. Payload compression needs payloads.
3. Cheaper isn’t free. The judge flagged it: the “list recent commits” question repeatedly scored 2/5 under Headroom, because compression mangles high-entropy commit SHA hashes. For tasks that depend on verbatim identifiers — hashes, tokens, IDs — lossy text compression is risky. Most other answers held at 4–5/5.
When to run both
Large result payloads (logs, file contents, big JSON) → YES: AGW Search/Code + Headroom stacks (−36% to −63%)
Small, catalog-dominated workload → AGW alone; Headroom can hurt (prefix-cache busting)
Tasks needing exact IDs (SHAs, tokens, hashes) → be careful: Headroom can mangle them
Any MCP tool-calling agent → Headroom needs --no-cache --no-ccr-* to not break
They’re complementary, not competing — AGW on the catalog, Headroom on the payload — and on the right workload they genuinely compound.
Reproduce it yourself
git clone https://github.com/sebbycorp/agentgateway-demos.git
cd agentgateway-demos/105-ent-headroom-comp-tokenomics
cp .env.example .env # AGENTGATEWAY_LICENSE_KEY, OPENAI_API_KEY, GITHUB_PAT (read-only), REPO_LARGE
set -a; . .env; set +a
./deploy.sh # kind + AGW + GitHub MCP backends + installs the Headroom proxy
./test.sh # one question, Headroom OFF vs ON
REPO_LARGE=owner/big-readonly-repo ./run_matrix.sh # full 12-cell matrix + LLM-judge
A Grafana dashboard (AGW Tool Modes + Headroom) visualizes cost, tokens, and quality OFF vs ON. You can even replay a saved run into Prometheus with observability/replay_to_pushgateway.py — no extra LLM spend:
kubectl port-forward svc/grafana -n observability 3001:80
Clean up with ./cleanup.sh.
Takeaways
- AGW tool modes and Headroom stack on large payloads — large repo: Code −63%, Search −36%. Different layers, real compounding.
- Headroom is payload-dependent. No payload, no benefit — and it can regress cache-friendly workloads by busting the prompt cache (Standard, small repo: +49% cost).
- Mind the accuracy cost. Compression mangles exact identifiers like commit SHAs; gate any compression layer with an answer-quality check.
- Headroom is not a clean drop-in for MCP. Its semantic cache + CCR tool-injection break tool-calling; disable them with
--no-cache --no-ccr-inject-tool --no-ccr-marker. - Measure for your own workload. This is a single run on two repos — the verdict flips with payload size, just as the 104 tool-modes study flipped with catalog size.
The full repo, manifests, harness, judge, and dashboard: 👉 github.com/sebbycorp/agentgateway-demos/tree/main/105-ent-headroom-comp-tokenomics
Related reading: