I’ve already covered the production OTel Collector pattern for shipping agentgateway traces to Langfuse. This is the opposite end of the spectrum: the absolute minimum that works.
No collector. No sidecar. No extra containers. Just the agentgateway binary running standalone, pointing its OTLP exporter directly at a self-hosted Langfuse on another VM. If you want LLM tracing on your laptop or a single box in about five minutes, this is the path.
Full working config:
sebbycorp/agentgateway-demos/08-standalone-langfuse
The data path
your app ──▶ agentgateway (:3000) ──▶ vLLM / Qwen backend
│
└── OTLP/HTTP traces ──▶ Langfuse VM (:3000/api/public/otel)
That’s the whole thing. agentgateway natively emits OpenTelemetry traces using the GenAI semantic conventions (gen_ai.request.model, gen_ai.usage.input_tokens, gen_ai.operation.name, …). Langfuse exposes a built-in OTLP receiver at /api/public/otel, so the gateway talks to it directly — no translation layer in between.
The only requirement: the box running agentgateway needs network access to the Langfuse host on port 3000.
Why no collector?
The collector pattern earns its keep when you need gRPC, batching, fan-out to multiple backends, or central enrichment at scale. For a single gateway sending to a single Langfuse, all of that is overhead.
| Standalone (this guide) | OTel Collector | |
|---|---|---|
| Moving parts | 1 binary | gateway + collector deployment |
| Protocol | OTLP/HTTP only | gRPC or HTTP |
| Auth handling | inline header (substituted at launch) | collector holds the secret |
| Best for | laptops, single VM, demos, MVP | clusters, multi-backend, prod |
If you outgrow it, the collector article is the next step. For now, keep it simple.
Prerequisites
- The
agentgatewaybinary on yourPATH(or sitting next to the config). - A reachable Langfuse instance. Mine is self-hosted at
http://172.16.10.112:3000. - A Langfuse public key and secret key (Project Settings → API Keys).
- An LLM backend. I’m pointing at a local vLLM serving
Qwen/Qwen3.6-35B-A3B-FP8at172.16.10.173:8000.
Quick reachability check before you start:
curl -I http://172.16.10.112:3000 || echo "Cannot reach Langfuse VM"
The config
Everything lives in one config.yaml. Here’s the tracing block — the part that matters:
config:
tracing:
# Langfuse OTLP HTTP endpoint (gRPC is NOT supported by Langfuse ingest).
# EU cloud: https://cloud.langfuse.com/api/public/otel
# US cloud: https://us.cloud.langfuse.com/api/public/otel
# Self-hosted: http://<host>:3000/api/public/otel
otlpEndpoint: http://172.16.10.112:3000/api/public/otel/v1/traces
# IMPORTANT: force HTTP (protobuf/json). The default is grpc.
otlpProtocol: http
headers:
Authorization: '"Basic ${LANGFUSE_AUTH_STRING}"'
x-langfuse-ingestion-version: '"4"'
# 1.0 / true for dev. Lower this in prod (e.g. 0.1).
randomSampling: true
Two things trip people up here, both of them about CEL:
otlpProtocol: httpis mandatory. agentgateway defaults to gRPC, and Langfuse’s ingest endpoint does not speak gRPC OTLP. Leave it on the default and traces silently never arrive.- Header values are CEL expressions, not raw strings. That’s why the values are double-quoted:
'"Basic ${...}"'. The outer quotes are YAML; the inner quotes make it a CEL string literal. Drop the inner quotes and the gateway tries to evaluateBasic ...as an expression and fails to parse.
Enriching the traces
The default GenAI spans are good, but a few extra fields turn them into something genuinely useful in Langfuse:
fields:
add:
# The actual conversation → Langfuse maps these to trace input/output.
# string() casts raw body bytes to text (else you get base64).
gen_ai.prompt: 'string(request.body)'
gen_ai.completion: 'string(response.body)'
gen_ai.request.stream: 'json(request.body).stream'
# Attribution / multi-tenant — pulled from request headers.
user.id: 'request.headers["x-user-id"]'
session.id: 'request.headers["x-session-id"]'
environment: '"local-dev"'
client.ip: 'source.address'
The user.id line is the one to notice — it’s what produces the per-user cost breakdown you’ll see in Langfuse later. No app changes required; the gateway is the instrumentation point.
The backend
binds:
- port: 3000
listeners:
- name: spark-http
protocol: HTTP
routes:
- name: spark-route
backends:
- ai:
name: spark
provider:
openAI:
model: "Qwen/Qwen3.6-35B-A3B-FP8"
hostOverride: "172.16.10.173:8000"
This uses the openAI provider type (vLLM speaks the OpenAI API) with hostOverride pointing at the local vLLM server.
The secret-substitution gotcha
You’ll notice the config contains the literal placeholder ${LANGFUSE_AUTH_STRING}. agentgateway does not expand environment variables when it reads YAML. If you source .env and launch the binary directly, it takes the literal string ${LANGFUSE_AUTH_STRING}, tries to parse it as CEL, and crashes:
Error: parse: ... Syntax error: token recognition error at: '$'
| Basic ${LANGFUSE_AUTH_STRING}
The fix is a tiny wrapper that substitutes the value into a temp file right before launch — keeping the real secret out of the committed config:
#!/bin/bash
set -euo pipefail
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
# Load secrets from .env (gitignored)
set -a; source "${SCRIPT_DIR}/.env"; set +a
# Substitute into a throwaway config; clean it up on exit
CONFIG_FILE=$(mktemp)
trap 'rm -f "$CONFIG_FILE"' EXIT
if command -v envsubst >/dev/null 2>&1; then
envsubst < "${SCRIPT_DIR}/config.yaml" > "$CONFIG_FILE"
else
sed "s|\${LANGFUSE_AUTH_STRING}|${LANGFUSE_AUTH_STRING}|g" \
"${SCRIPT_DIR}/config.yaml" > "$CONFIG_FILE"
fi
exec agentgateway -f "$CONFIG_FILE" "$@"
Build the auth string once and drop it in .env:
echo -n "$LANGFUSE_PUBLIC_KEY:$LANGFUSE_SECRET_KEY" | base64
# → put the result in .env as LANGFUSE_AUTH_STRING=...
This is the same pattern you use for any proxy that doesn’t do env expansion natively (Envoy-style tools). .env stays gitignored; config.yaml stays clean.
Run it
chmod +x run.sh
./run.sh
You should see the startup logs print the substituted tracing block — the Authorization header should now read Basic cG..., not the ${LANGFUSE_AUTH_STRING} placeholder. That one line is your fastest confirmation the substitution worked.
Verify the gateway in the UI
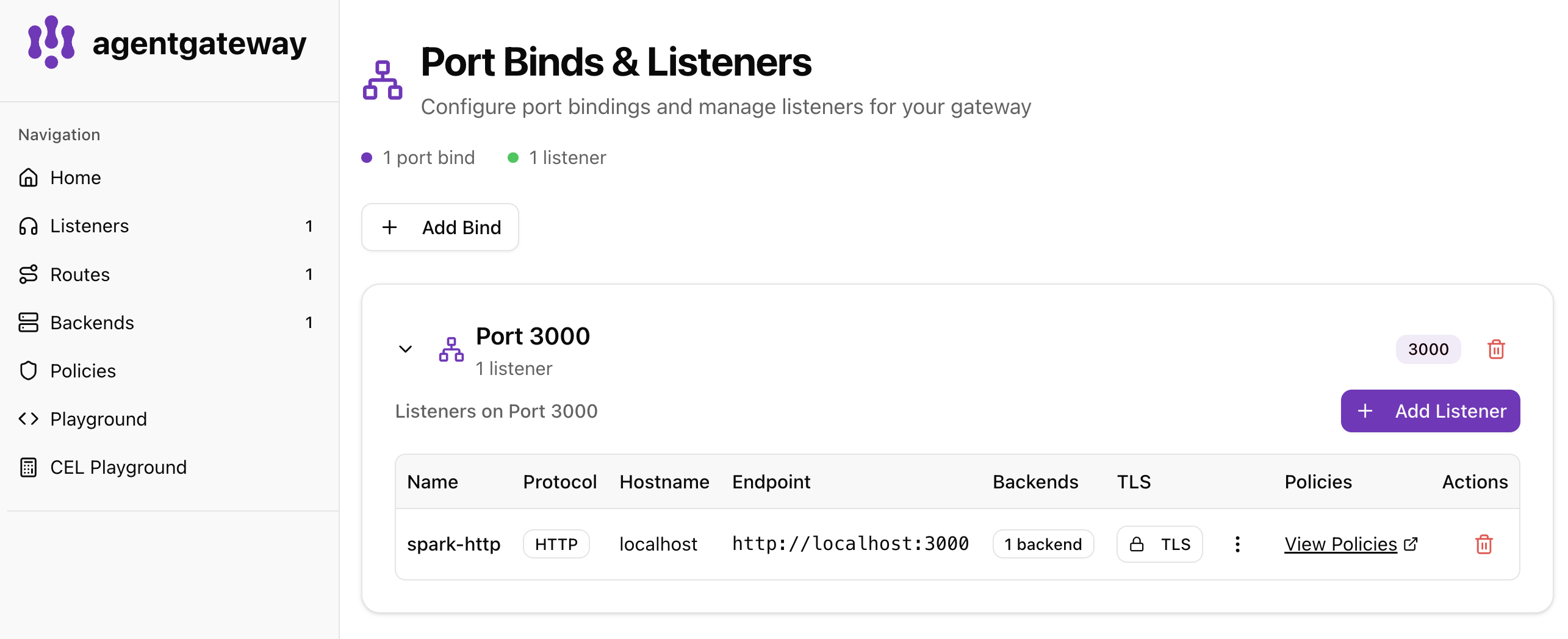
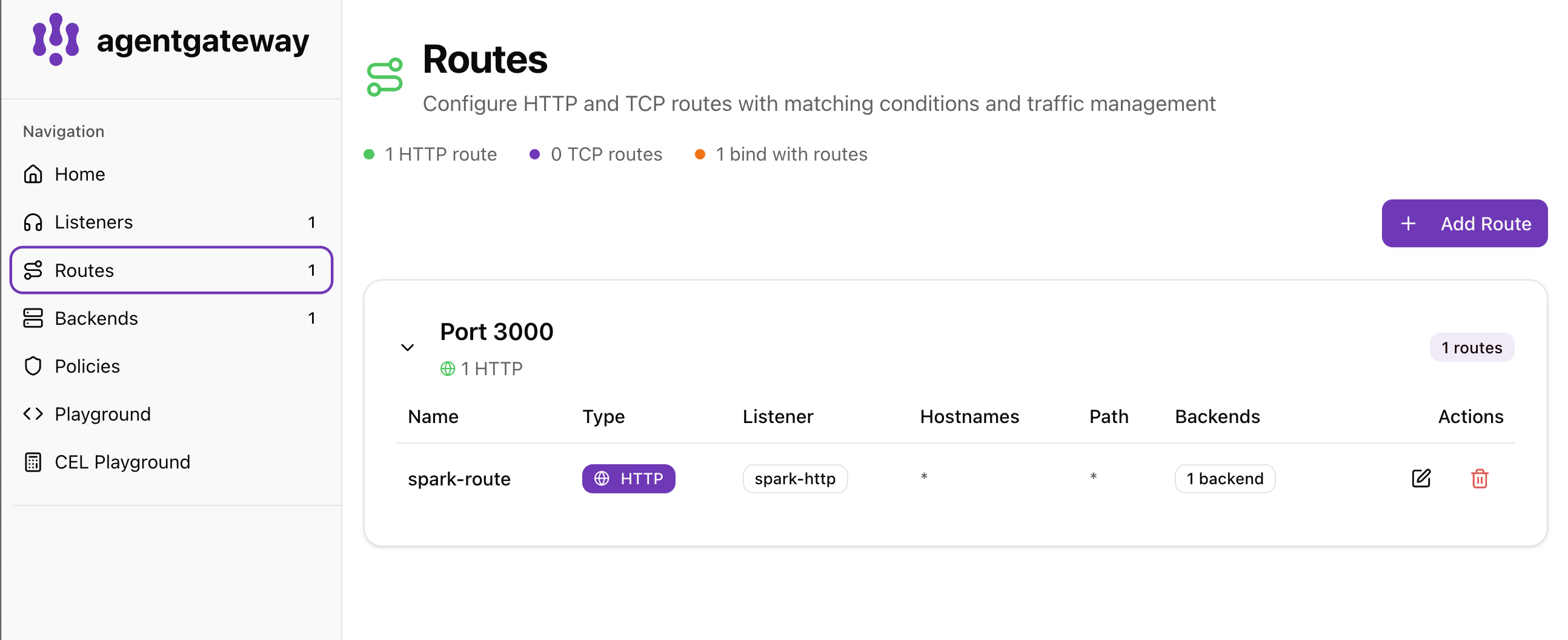
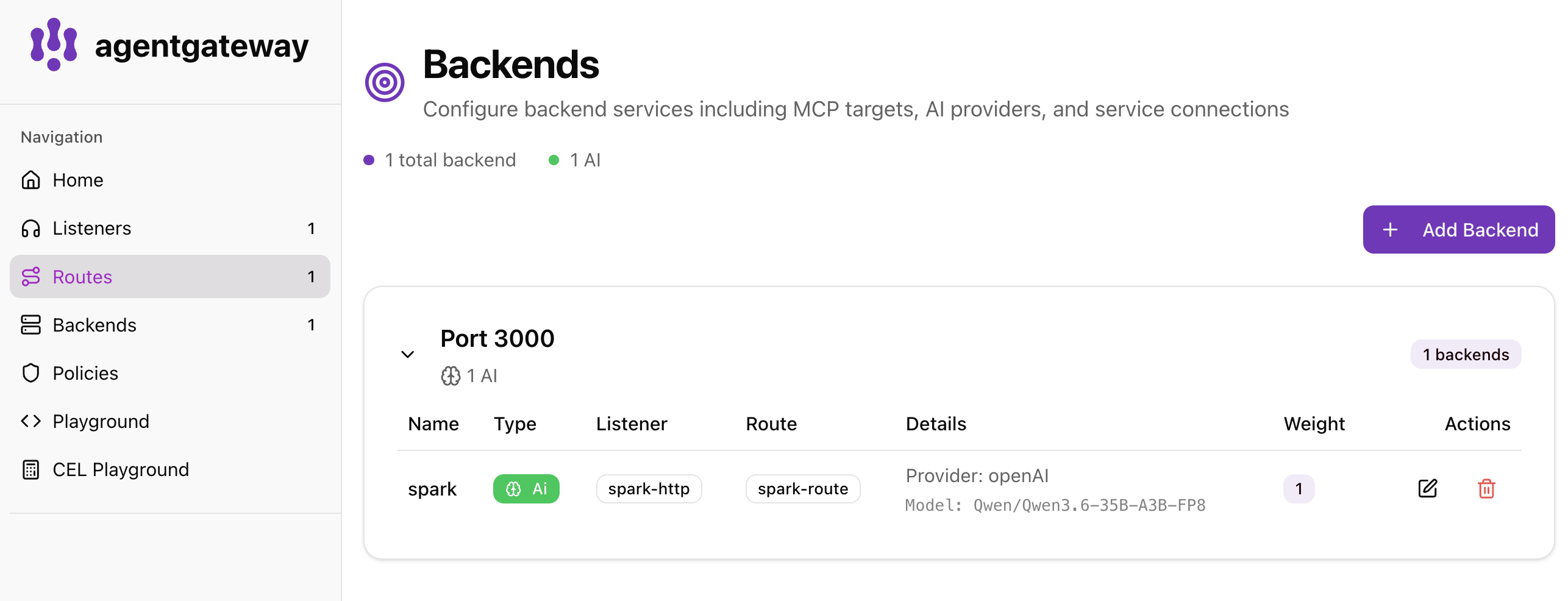
agentgateway ships a local UI. Open it and you should see the bind, the route, and the AI backend all wired to port 3000.
Listeners — one HTTP listener (spark-http) bound to port 3000:
Routes — spark-route attached to the spark-http listener, matching all hosts and paths:
Backends — the spark AI backend, provider OpenAI-compatible, model Qwen/Qwen3.6-35B-A3B-FP8:
Send some traffic
Anything that hits the OpenAI-compatible endpoint on port 3000 gets traced. The key is passing x-user-id and x-session-id headers so the gateway can attribute each trace:
curl -X POST "http://localhost:3000/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "x-user-id: alice" \
-H "x-session-id: demo-session-1" \
-d '{
"model": "Qwen/Qwen3.6-35B-A3B-FP8",
"messages": [{"role": "user", "content": "Explain OTLP in one sentence."}],
"temperature": 0.7,
"stream": false
}'
The repo’s test.sh automates this — it loops over a handful of demo users (alice, bob, carol, dave, erin) with different traffic weights and supports streaming via --stream, which is exactly how you generate the per-user breakdown below:
chmod +x test.sh
./test.sh # non-streaming
./test.sh --stream # SSE streaming
See it in Langfuse
Open your Langfuse project. Within a second or two of sending traffic (that’s what x-langfuse-ingestion-version: "4" buys you — real-time previews), traces start landing. Because the gateway emits proper GenAI conventions, Langfuse renders them as full generations with model, token counts, latency, and cost — even for a local Qwen model.
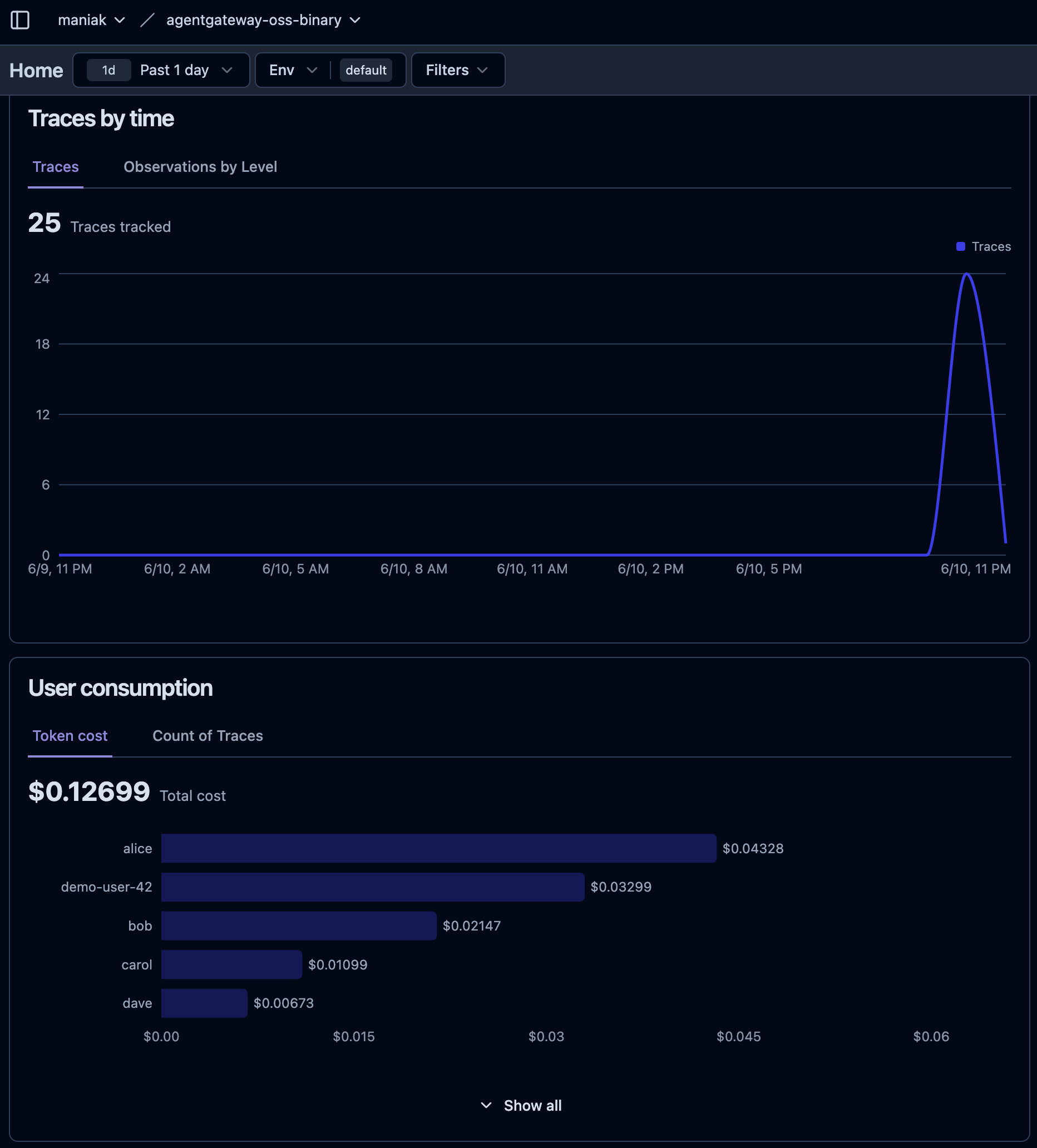
That User consumption panel is the payoff of the user.id field in the config — total spend broken out per user (alice $0.04328, bob $0.02147, and so on), all from a gateway that the LLM apps never had to be aware of.
Troubleshooting
Traces never appear.
- Confirm the gateway box can reach Langfuse:
curl -I http://172.16.10.112:3000. - Check the startup logs show the real
Authorization: Basic cG...header, not the${...}placeholder. If it’s still the placeholder, you launched the binary directly instead of viarun.sh. - Make sure
otlpProtocol: httpis set — gRPC silently fails against Langfuse.
Syntax error: token recognition error at: '$' — the literal placeholder reached the binary. Use run.sh (or envsubst) so the secret is substituted before launch.
Inputs/outputs show as base64 in Langfuse — wrap the body fields in string(...), as in the fields.add block above.
When to graduate to a collector
Stay standalone for laptops, single VMs, demos, and MVPs — one binary, one config, done. Reach for the OTel Collector pattern when you need gRPC from the gateway, batching and retries under load, fan-out to more than one observability backend, or you simply don’t want the Langfuse secret living anywhere near the gateway process.
Same traces, same GenAI conventions — just a heavier, more flexible delivery path. Start here; grow into that.
Get the code
The complete, runnable setup — config.yaml, run.sh, and test.sh — lives in my demos repo:
→ github.com/sebbycorp/agentgateway-demos/tree/main/08-standalone-langfuse
Clone it, drop your keys into .env, and ./run.sh:
git clone https://github.com/sebbycorp/agentgateway-demos.git
cd agentgateway-demos/08-standalone-langfuse